Make it 'Byte'-Sized
Overview and Table of Contents
With the shattering of performance benchmarks and the development of applications like ChatGPT and Bing Chat, lots of time and writing has been dedicated to demystifying advancements in neural network architectures. But advancements in tokenization, a necessary preprocessing step often take place with less publicity. In this post, we’ll lend a little love and spotlight to the topic. We’ll review what tokenization is, why it’s done and walk through the details behind both simple and more complex, recent developments and approaches.
- Tokenization: What It Is and Why It’s Done
- Word & Subword Level Methods
- Byte-Level Byte Pair Encoding
- References
Tokenization: What It Is and Why It’s Done
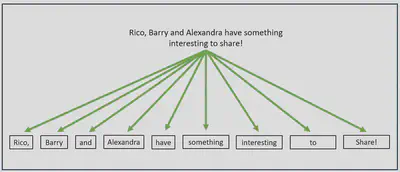
Tokenization is the splitting up of a text into some concept of ‘atomic’ units: words or sub-word units, for example. In order to utilize advancements in neural networks for natural language processing (NLP), we first need a way to convert text into a machine learning digestible format. Tokenization is the first step in this process; it allows us to break a text into contributing components. Those components are then typically mapped to vectors, through an embedding layer, and can be fed into a neural network.
How text should be decomposed isn’t obvious and lots of differing approaches exist. The example pictured above is a simple example: namely, splitting at every space character. While such methods do have use-cases, many modern NLP pipelines also utilize more sophisticated methods. We’ll touch on some of these in the upcoming sections, looking at methods on the word, subword and byte levels, culminating with an introduction to the approach used in models like RoBERTa and GPT 3.5 & 4.
Word & Character Level Methods
Word-Level Methods
Why not separate characters by spaces? Let’s think about what typically happens after tokenization, namely, embedding. For every token in our vocabulary, we’ll generate' an embedding vector. That means that the size of our embedding matrix or model will scale with the size of our vocabulary. You’ll notice that, in splitting by spaces, punctuation gets lumped in with words. Do we really want to include all of “share”, “share!”, “share?” and any other punctuation combinations in the corpus as separate tokens? Not dealing with punctuation could lead to massive inefficiencies.
As an improvement, we could try to additionally split around punctuation. In other words, our initial example would get tokenized as
import re
TEXT = "Rico, Barry and Alexandra have something to share!"
re.findall( r'\w+|[^\s\w]+', TEXT)
['Rico',',','Barry','and','Alexandra','have','something','to','share','!']
A different example might highlight some lingering deficiencies, though.
TEXT = "I don't wanna keep secrets just to keep you."
re.findall( r'\w+|[^\s\w]+', TEXT)
["I", "don","'","t","wanna","keep","secrets","just","to","keep","you","."]
There’s something unintuitive about the way “don’t” was split. We know “don’t” stands for “do not” and so, it might be better to tokenize it as
["I","do","n't","wanna","keep","secrets","just","to","keep","you","."]
Here’s another one:
TEXT = "The Labour party currently holds 199 seats in the U.K. parliament."
re.findall( r'\w+|[^\s\w]+', TEXT)
["The", "Labour","party","currently","holds","199","seats","in","the","U",".","K",".","parliament","."]
We know that the “U.K.” is an abbreviation, representing a single entity so splitting it by punctuation doesn’t make much sense. What we’re getting at with these examples is that there are additional rules and rule-exceptions that a simple punctuation and/or space based approach doesn’t take into account.
With that in mind, there are a number of popular rule-based, word-level
tokenizers, like those in spaCy that can
accomodate for these exceptions and others. In short, spaCy’s
documentation describes their tokenization algorithms broadly as first
splitting on white space and then, processing from left to right,
performing the two following checks:
- Does the substring match a tokenizer exception rule?
- Can a prefix, suffix or infix be split off?
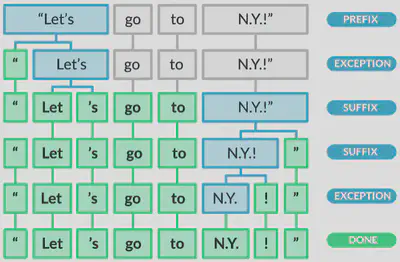
spaCy tokenization.
Revisiting the last code example, we can use spaCy’s rule-based
tokenizer as follows:
import spacy
TEXT = "The Labour party currently holds 199 seats in the U.K. parliament."
nlp = spacy.load("en_core_web_sm")
doc = nlp(TEXT)
print([token.text for token in doc])
['The','Labour','party','currently','holds','199','seats','in','the','U.K.','parliament','.']
Subword-Level Methods
In some cases, subword-level tokenization offers potential advantages.
This is especially true when the text corpus is large, the language
model has a fixed size vocabulary and/or handling of rare or novel words
(relative to the training set) is necessary (either as input or for
generation). In fact, because of the revitalized modern interest in
subword-level tokenization, typographically based tokenizers like those
discussed in the previous section are sometimes referred to as
‘pre-tokenizers’; they are often applied prior to tokenization as a
preprocessing step. In addition to spaCy, a number of implementations
can be found in the pre_tokenizers
module of the HuggingFace tokenizers
Python package.
A lage text corpus, fixed vocabulary size and/or out of vocabulary (OOV) tokens: why might subword-level tokenizers show relative advantages given these restrictions? Let’s assume we’re still working at the word level. A large text corpus means a potentially prohibitively large vocabulary. A fixed vocabulary means potentially being highly susceptible to poor OOV handling. And, in the same vein, an ability to handle OOV well would potentially require a prohibitively large vocabulary. Clearly, all of these scenarios are related and subword-level tokenization can help address each of them via the following obvious fact: words can be decomposed into subwords. As an example, consider the BERT tokenizer:
from transformers import BertTokenizer
TEXT = "Tokenizers"
tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
tokenizer.tokenize(TEXT)
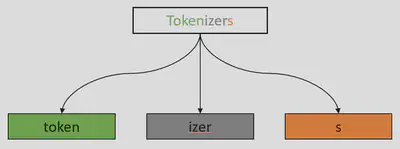
Consider the challenge of having a large text corpus. If sub-word units are chosen intelligently, we can take advantage of the fact that lots of words tend to be decomposable into a set of shared units. In other words, tokenizing at the subword level has the potential to drastically shrink the vocabulary size. By the same reasoning, in some sense, more information can be captured into a fixed vocabulary at the subword level than at the word level. And lastly, presented with novel words, assuming their subword components have been seen before, those words can still be processed and/or generated directly.
Let’s concretize this with some examples.
Byte Pair Encoding
Byte Pair Encoding (or BPE) originates from the world of data compression (Philip Gage, 1994). The main idea is simple. Given a sequence of bytes to be streamed:
- Identify the byte-pair that appears most frequently.
- Replace said byte-pair with a single byte, not observed in the original sequence.
- Take note of this substitution in a table, call it $T$.
- Repeat steps 1-3 until the data has been sufficiently compressed.
- Send $T$ ahead of the resulting, compressed byte sequence.
The application of BPE to tokenization (to my knowledge) was first due to (Senrich et al., 2016) and is a fairly straightforward modification. Namely, the method, as described in the 2016 paper, roughly boils down to the following algorithm:
- Initialize the vocabulary with the set of symbols making up the corpus.
- Represent each word as a sequence of these characters.
- Extract a dictionary of these word-based character sequences, weighted by the frequency of each word’s occurrence in the corpus.
- Iteratively count all symbol pairs and replace each occurrence of the most frequent pair (‘A’, ‘B’) with a new symbol ‘AB’.
- Repeat step 4 until the desired vocabulary size is reached.
The resulting vocabulary will have a size equal to cardinality of the initial character set plus the number of implemented merge operations (which can be treated as a hyperparameter). Senrich et al. provide the following minimal implementation of BPE in Python:

Using BPE in this way became somewhat of a standard in sub-word tokenization because it enables a tokenizer to learn a balance between character and word-level tokens and makes progress in addressing vocabulary size and OOV problems. Still, these are potential problems, especially in the subdomain of neural machine translation where the potential character sets among all relevant languages may, yet, be prohibitively large.
The algorithm implemented by ChatGPT models and others take advantage of modern character encoding methods to modify BPE in a way that accounts for these challenges. But, before we pull that thread further, let’s look at another (similar) sub-word level tokenization algorithm: ‘WordPiece’.
WordPiece
WordPiece is brought to us by two former employees at Google: Mike Schuster and Kaisuke Nakajima via Japanese and Korean Voice Search (2012). Similar to BPE, WordPiece is a data-driven, greedy algorithm designed to intelligently construct subword units from a corpus of text. Where the methods differ is stictly related to how they define that locally optimal merge at each step; what does it mean for a pair of tokens to be the ‘best’ merge pair? With BPE, it was simply frequency. In the case of WordPiece, it’s likelihood.
What likelihood, you might ask? The likelihood of the training data, according to some language model (say unigram on tokens, for example). Intuitively, what we’re doing is prioritizing merges where the resultant unit occurrs frequently, relative to it’s constituent units. Here’s the algorithm, as presented by Schuster and Nakajima:

Just as was the case with BPE, WordPiece improves, but still doesn’t solve all vocabulary size restrictions and OOV problems. In the next section, we’ll see how some modifications to BPE can get us closer.
Byte-Level Byte Pair Encoding
Earlier, we mentioned leveraging modern character encoding processes. Recall that using the Unicode standard, every written character, spanning all languages, can be uniquely represented as numbers (or codepoints). Encoding algorithms, like UTF-8, for example, take those numbers and represent them as byte sequences.
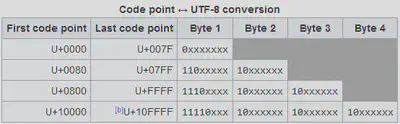
That every character can be translated into a sequence of bytes is an observation we can use to our advantage. Namely, instead of applying the BPE algorithm to characters, as previously illustrated, Byte-Level BPE (as the name suggests) applies the same algorithm to bytes. That’s it!
What makes this appealing? Well, there are only $2^8=256$ possible bytes , resulting in a small base vocabulary and because every character can be represented as a byte sequence, this means that we’ve side-stepped the OOV problem. In other words, we get incredible scope with a relatively small vocabulary. To put this in perspective, to accomplish the same scope using characters would require a base vocabulary of $\approx150,000$.
But it’s not all good news. Decomposing characters to work at the level of bytes means longer token sequences, resulting in longer training and inference times. That said, for many use cases, the tradeoff is worth it. Indeed, Models like RoBERTa and GPT$\geq2$ use Byte-Level BPE implementations.
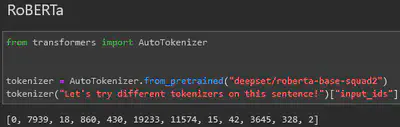
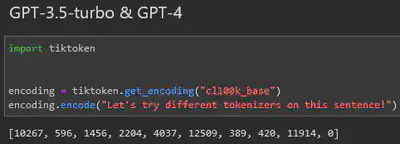
To read more about the GPT models implementation, see section $2.2$ of Language Models are Unsupervised Multitask Learners (Radford et al.)
References
[2] Radford, Alec, et al. Languagte Models Are Unsupervised Multitask Learners, 2019